Dump Tweet data into Data Lake¶
Requirements¶
Come up with a Data Lake storage system.
Data lake setup should be as follows on our HDFS, basically boils down to HDFS paths:Bronze Lake : Raw data i.e tweets
Silver Lake : Preprocessed data like running some kind of NLP stuff like Nammed Entity Recoginition (NER), cleansing etc.,
Gold Lake : Data Ready for web application / dash board to consume
Have provision to collect tweets:
Related to
Data Science/AI/Machine Learning/Big Dataand dump into bronze lakeMore generic along side of above tweets
Implementation Steps¶
Get API Credentials from Twitter Developement Site
Setup Tweepy to read Twitter stream filtering tweets that talks about
Data Science/AI/Machine Learning/Big DataCreate Kafka topics for twitter stream
Dump the tweets from Tweepy into Kafka topics
Use Spark Structured Streaming to read the Kafka topic(s) and store as parquet in HDFS
Use HDFS command line ot verify the data dump
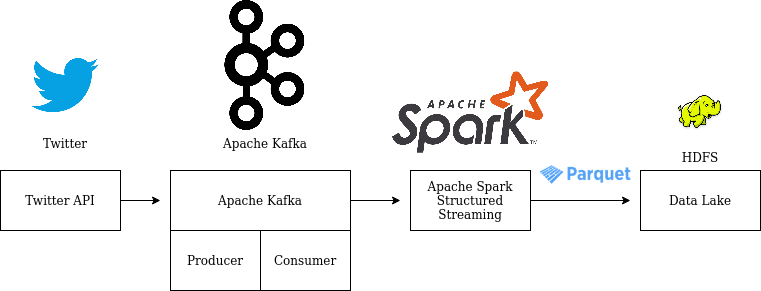
Data flow path:
Twitter API -> Kafka Producer (two topics) -> Kafka Server
Spark Structured Streaming with Kafka Consumer -> Parquet Sink -> Bronze Lake (HDFS location)
Configuration¶
Config file used : default_ssp_config.gin
How to run?¶
There are two ways of running, that is on docker or on your local machine. In either case, opening the terminal is the difference, once the terminal is launched, the steps are common.
Start the docker container, if needed:
docker run -v $(pwd):/host/ --hostname=$(hostname) -p 50075:50075 -p 50070:50070 -p 8020:8020 -p 2181:2181 -p 9870:9870 -p 9000:9000 -p 8088:8088 -p 10000:10000 -p 7077:7077 -p 10001:10001 -p 8080:8080 -p 9092:9092 -it sparkstructuredstreaming-pg:latest
To get a new terminal for our docker instance run :docker exec -it $(docker ps | grep sparkstructuredstreaming-pg | cut -d' ' -f1) bash
Note: We pull our container run id with $(docker ps | grep sparkstructuredstreaming-pg | cut -d' ' -f1)
This example needs three terminals:
Producer bin/data/start_kafka_producer.sh
Twitter API -> Kafka Producer -> Kafka Serversrc/ssp/spark/streaming/consumer/twiteer_stream_consumer_main.py
Consumer bin/data/dump_raw_data_into_bronze_lake.sh
Spark Structured Streaming with Kafka Consumer -> Parquet Sink -> Bronze Lakesrc/ssp/spark/streaming/consumer/twiteer_stream_consumer_main.py
spark-submitis used to run the application.Which submits the application to Spark master, if the application has SparkSession in it, then it will be considered as Spark Application and the cluster is used to run the application
Since cluster is involved in our example, we need to specify the number of cores, memory needed and maximum cores for our application, which is exported just before the spark-submit command in the shell script file.
Also the extra packages need for the application is given as part of the submit config
HDFS
Command line tool to test the parquet file storage
On each terminal move to source folder
If it is on on local machine
#
cd /path/to/spark-streaming-playground/
If you wanted to run on Docker, then ‘spark-streaming-playground’ is mounted as a volume at
/host/
docker exec -it $(docker ps | grep sparkstructuredstreaming-pg | cut -d' ' -f1) bash
cd /host
[producer] <- custom (guake) terminal name!
export PYTHONPATH=$(pwd)/src/:$PYTHONPATH
vim bin/data/start_kafka_producer.sh
bin/data/start_kafka_producer.sh
[visualize]
export PYTHONPATH=$(pwd)/src/:$PYTHONPATH
vim bin/data/visulaize_raw_text.sh
bin/data/visulaize_raw_text.sh
[consumer]
export PYTHONPATH=$(pwd)/src/:$PYTHONPATH
vim bin/data/dump_raw_data_into_bronze_lake.sh
bin/data/dump_raw_data_into_bronze_lake.sh
[hdfs]
export PYTHONPATH=$(pwd)/src/:$PYTHONPATH
export PYTHONPATH=$(pwd)/src/:$PYTHONPATH
hdfs dfs -ls /tmp/ssp/data/lake/bronze/delta/
Take Aways / Learning’s¶
Understand how to get an Twitter API
Learn to use Python library Tweepy to listen to Twitter stream
Understand creation of Kafka topic
--create --zookeeper localhost:2181 \ --replication-factor 1 --partitions 20 --topic {topic}```
Dumping the data to Kafka topic : TweetsListener
Define
KafkaProducerwith Kafka master urlSend the data to specific topic
Using Spark Structured Streaming to read Kafka topic
Configuring the read stream
Defining the Schema as per Twitter Json schema in our code
Using Spark Structured Streaming to store streaming data as parquet in HDFS/local path
View the stored data with HDFS commands
Limitations / TODOs¶
The free Twitter streaming API is sampling 1% to 40% of tweets for given filter words. So how to handle to full scale real time tweets with services like Gnip Firehose?
Have common APIs for all File systems : Local Disk, HDFS, AWS S3. GFS
Understand more on Kafka topic creation and its distribution configuration paramaters like partitions, replicas etc.,
Come up with Apache Spark Streaming Listeners, to monitor the streaming data